299€ or 2 x 149.00€
For aspiring Deep Learning Professionals looking to build ready-to-deploy models and make a bigger impact.
🌒 ECLIPSE: COURSE HAS BEEN ECLIPSED. IT WILL NOW BE RESHARED AND REOPEN IN THE FUTURE. MAKE SURE TO JOIN THE DAILY EMAILS TO BE NOTIFIED.

.gif)
.gif)


The third course I have taken with Think Autonomous, won't be my last!
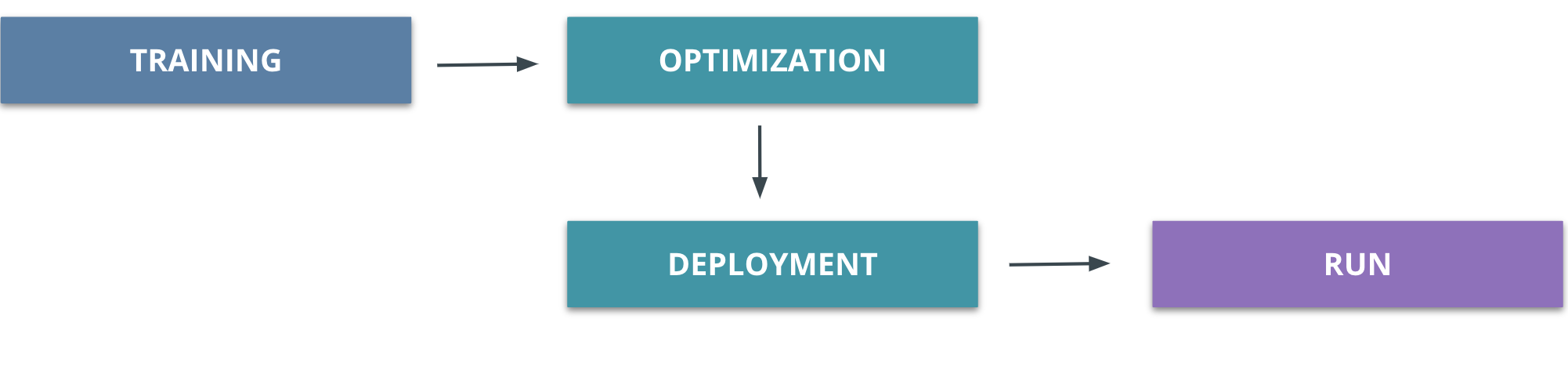
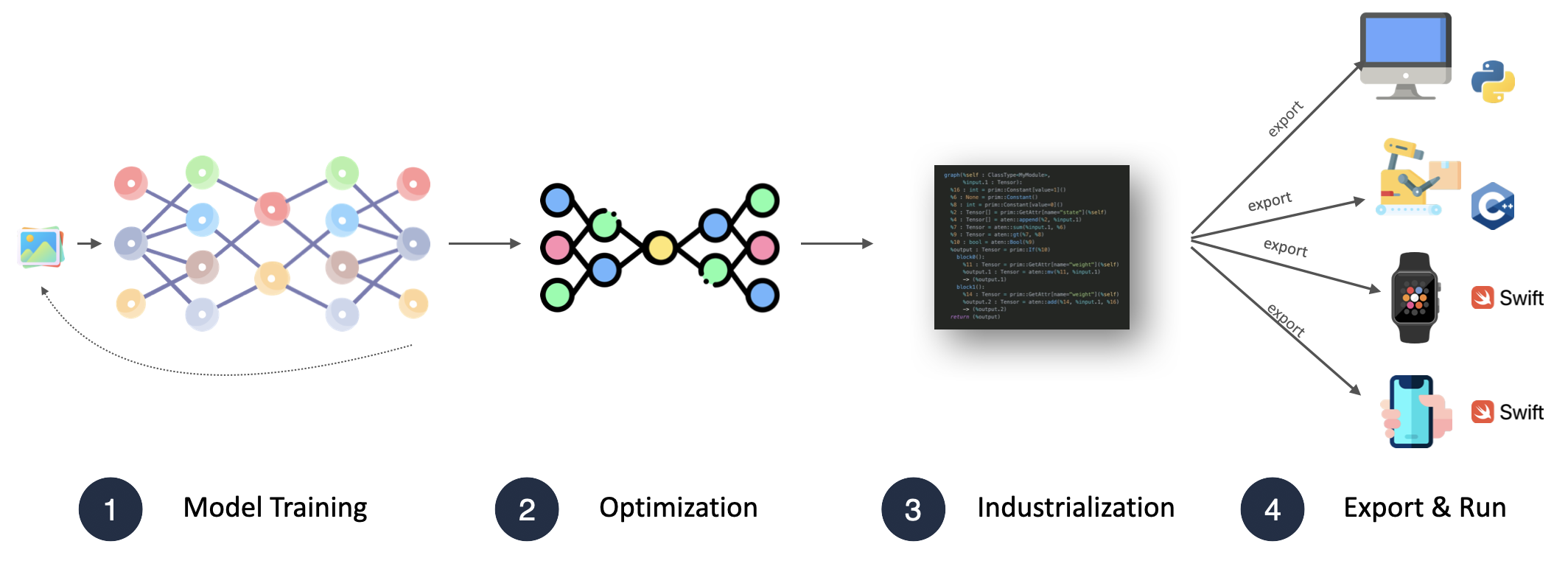
This course demystified popular techniques for optimizing models for deployment, and made them more approachable.
Great course!
A great course with thorough and clear explanation! Highly recommended!
Thanks for sharing the content. Am reading again and again.its the most distilled, crystal clear, laser sharp explanation of the topic.
Am still distilling the content word by word. Will go through both courses again (HydraNet and Neural optimization) to beef up my understanding having rearmed.
The inclusion of appendix was excellent move. Such addendum are great companion.keep doing for other courses.
299€ or 2 x 149.00€
For aspiring Deep Learning Professionals looking to build ready-to-deploy models and make a bigger impact.
Lifetime Access to:
The Pro Player Tactics to Optimize Models
The Model Deployment Guide
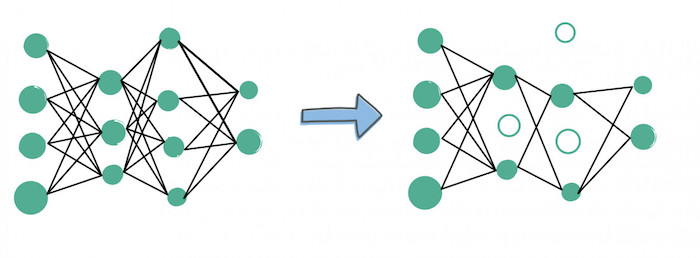
An In-Depth Look at Model Pruning, Knowledge Distillation, and Quantization
🌒 ECLIPSE: This course is now CLOSED since March 26, 2026. We are making a few updates to it - by adding a Deployment DLC — Join our Daily Emails to get notified of the reopening.