How to use the Dark Side of Deep Learning to make your models insanely faster... and ready to be deployed!
Have you ever been stuck with speed? Did you ever wonder if your models were "professional" enough, or what you needed to do to make them production ready?
Getting out of the Playground can be difficult.
I had similar issues, but through my research, I discovered 5 Deep Learning techniques used by researchers to make their models much faster, and deployable in tiny devices such as drones, or autonomous cars!
1. The Separable Convolution
If you run a 3x3 Convolution, it will be faster than if you run a 5x5 convolution, right? And if you run a 1x1 convolution, it's faster than a 3x3 convolution... but it doesn't product the same results!
A specific type of convolution, called Separable Convolution has been invented by researchers to not only have a good receptive field, but also demand less computations.
After some tests shared in this journey, we can see a 96% improvement using these operations.
2. HydraNets
Did you ever wonder, how does a car like a Tesla run so many models in parallel? Think about it, it needs to detect objects, but also find the drivable surfaces, predict the next positions, determine the equations of the lane lines, and run 3D Reconstruction. It also has a smart summon feature, a planning engine, and, of course, traffic light detection.
Is that even possible to implement all of that on a single computer?
Through my research, I found that a technique they're using is called the HydraNet... one network, several heads.
Here's an example: On these 2 Computer Vision tasks, semantic segmentation and depth estimation, we can see a 74% improvement.
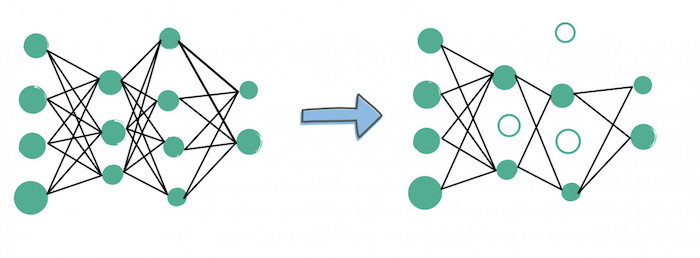
3. Model Pruning
Did you ever read the values of the neural network weights? If you look closely, you'll notice some of them are close to 0, which means that the connections have literally no impact on the network... Yet they consume lots of computations!
This is why a technique called Model Pruning helps learn, identify, and remove these connections.
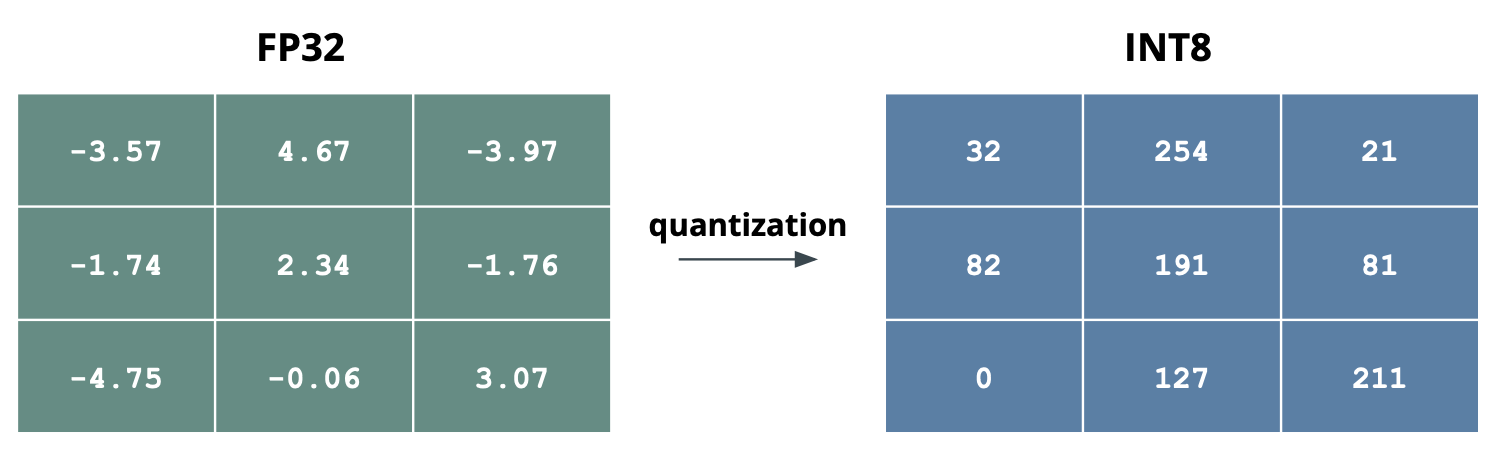
4. Weight Quantization
One of the most powerful technique is called Weight Quantization. This technique modifies the weights of a network to use faster numbers, without reducing the performance! This technique usually produces 2-4x faster inference.
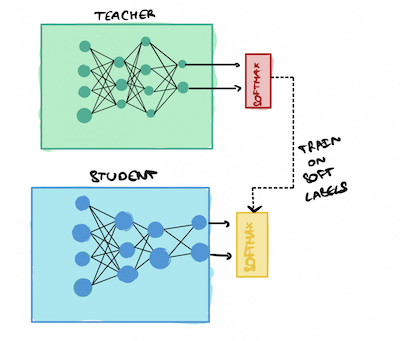
5. Knowledge Distillation
Do you think Yoda teaches everything he knows to Luke in Star Wars V? Of course not! Even though he learned so much from the force, he only teaches Luke what he knows! And this "Yoda" technique is used by researchers to transfer the knowledge between heavy and light neural networks. In this Journey, you'll see that this technique can boost your models up to 1,000%!
This Neural Optimization Pack is a combination of 2 courses that will teach you how to implement these 5 techniques, and one "Codex" bonus that will show you how to "export" them to production environments.
So let's begin with the first course, that will teach you HydraNets and Separable Convolutions:
COURSE #1
LEARN HYDRANETS: Monstrous Multi-Task Learning Techniques with PyTorch
Learn multi-task learning and build state-of-the-art 3D Segmentation systems with PyTorch
What's inside?
This first course will start with the fundamentals of buildingPyTorchmodelsthat solve more than one task, and will escalate to training and running models that can do joint semantic segmentationanddepthestimation. At the end, we'll learn to combine heads into 3D Segmentation outputs.
MODULE 1
Introduction to Multi-Task Learning with PyTorch
In the first module, we'll get familiar with the Multi-Task Learning algorithms implemented inside companies like Tesla, and we'll study the main rules and barriers in Multi-Task Learning.
MODULE 2
Advanced Multi-Task Learning for Self-Driving Cars
In the second module, we'll consolidate our PyTorch skills and implement an advanced research paper capable of doing Semantic Segmentation and Monocular Depth Estimation in Real-Time.
MODULE 3
Training Cutting-Edge Models with PyTorch
In the last module, we'll implement the training techniques used to come up with a state-of-the-art multi-task encoder/decoder network such as the one we used in Module 2.
BONUS ✨
Interview with a HydraNet Researcher
This course has been developed around a cutting-edge algorithm develop by a HydraNet Researcher. After the release of this course, I hunted for the creator of the HydraNet, and went to ask a few questions...
COURSE #2
Neural Optimization
For aspiringDeepLearningProfessionals looking to build ready-to-deploy models and make a bigger impact.
This course will teach you how to build ultra fast and ready-to-deploy models.
Here are a few things you'll learn:
11 Optimization Techniques You Can Use to 2x, 3x, or even 10x the FPS of your models (warning: some of these techniques require just a few minutes, while others will be long to implement but highly efficient — 2 of these techniques are unofficial "backdoor" techniques)
4 KPI METRICS you need to monitor in a Deep Learning model and how to calculate them with PyTorch (based on the old saying "you can't improve what you can't measure", we will develop a system you can use to measure every network you develop from now on)
The "Loki" technique to make your models incredibly lighter without reducing a drop of accuracy (this technique even contains "Variants" as explained in the course)
MODEL PRUNING PROJECT: Learn to PickaDataset, Traina Model, and Optimizeit using 3 different Model Pruning techniques.
The TESLA Development Cycle introduced by Andrej Karpathy to run HydraNets in a fleet of 200k+ cars on Autopilot.
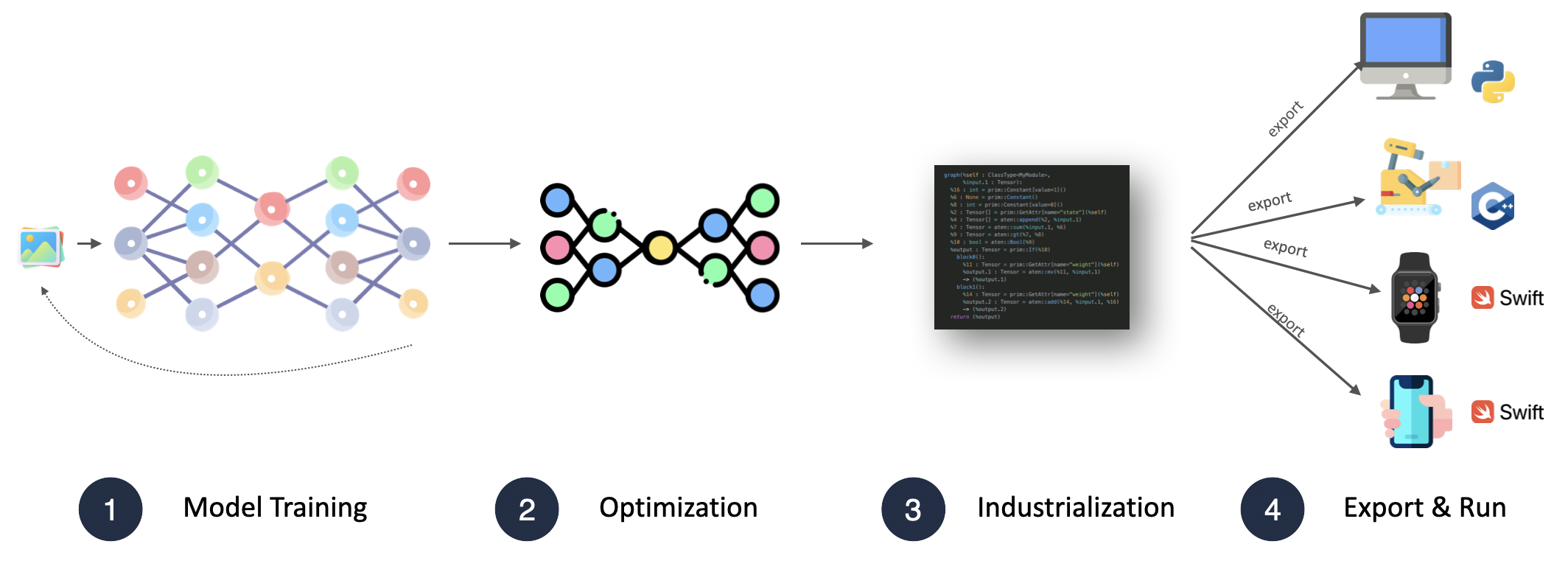
How to make Your Models Production-Ready and Exportable to C++, Swift, or any other languagewith PyTorch (if you're a Python Engineer who hates C++, this could mean working in C++ companies without being a bully)
THE 6-STEP FORMULA to Quantize Neural Networks with PyTorch (some of these steps will highly depend on your deployment environment)
WEIGHT QUANTIZATION PROJECT — Turn a slow Semantic Segmentation Model into a World-Class Star Algorithm.
The DARK KNOWLEDGE secret to distill knowledge from one network to another (warning: dark knowledge is almost a mystic art, only the experimented engineers should dare to go there)
The DISTILLATION LOSS Function Explained, Component-by-Component (this is another variant loss function, we'll go over the most popular one to build foundations)
HYDRA-DISTILLATION: How to use KnowledgeDistillation withHydraNets (warning: this is an advanced technique only feasible after you've been through the HydraNet course)
and many more...
Optimization, but also Industrialization.
The second course, Neural Optimization, has been built to complete this first course. It will teach you about Model Pruning, Weight Quantization, and Knowledge Distillation. But it will also go much further and show you how to professionally build and deploy Deep Learning pipelines. Although this course will spend lots of time on the "Optimization" part, we will aso talk about Industrialization and Exporting, as these are essential steps when shipping Deep Learning models.
Here are a few results, you will implement these techniquesFROM SCRATCH:
"A great course with thorough and clear explanation! Highly recommended!"
Arief Ramadhan, AI Engineer @ Nodeflux
"The third course I have taken with Think Autonomous, won't be my last! This course demystified popular techniques for optimizing models for deployment, and made them more approachable. Great course!"
Brandon Elford, AI Engineer @ Potential Motors
BONUS: The Neural Optimization Codex!
For the entries to the Pack during Email 1,000 only: you can get access to my Neural Optimization Codex, built to help engineers deploy their models to production environments.
"It's the most distilled, crystal clear, and laser sharp explanation on the topic."
Hello Jeremy,
Thanks for sharing the Codex. I am reading again and again. It's the most distilled, crystal clear, laser sharp explanation of the topic.
Thank you."
Abkul Orto, Edgeneer
€375 or 3 monthly payments of €135
THE NEURAL OPTIMIZATION PACK (Early 2022)
Closed
Bundle
2 Products
Master all possible ways to deploy cutting-edge models at Turbo speed.